Hello, this is Hao.
The month of May we celebrate Asian America and Pacific Islander heritage. So I decided to take a look at the Asian restaurants in the NYC area on yelp.com.
I will use R with the rvest package to scrape some data from the website.
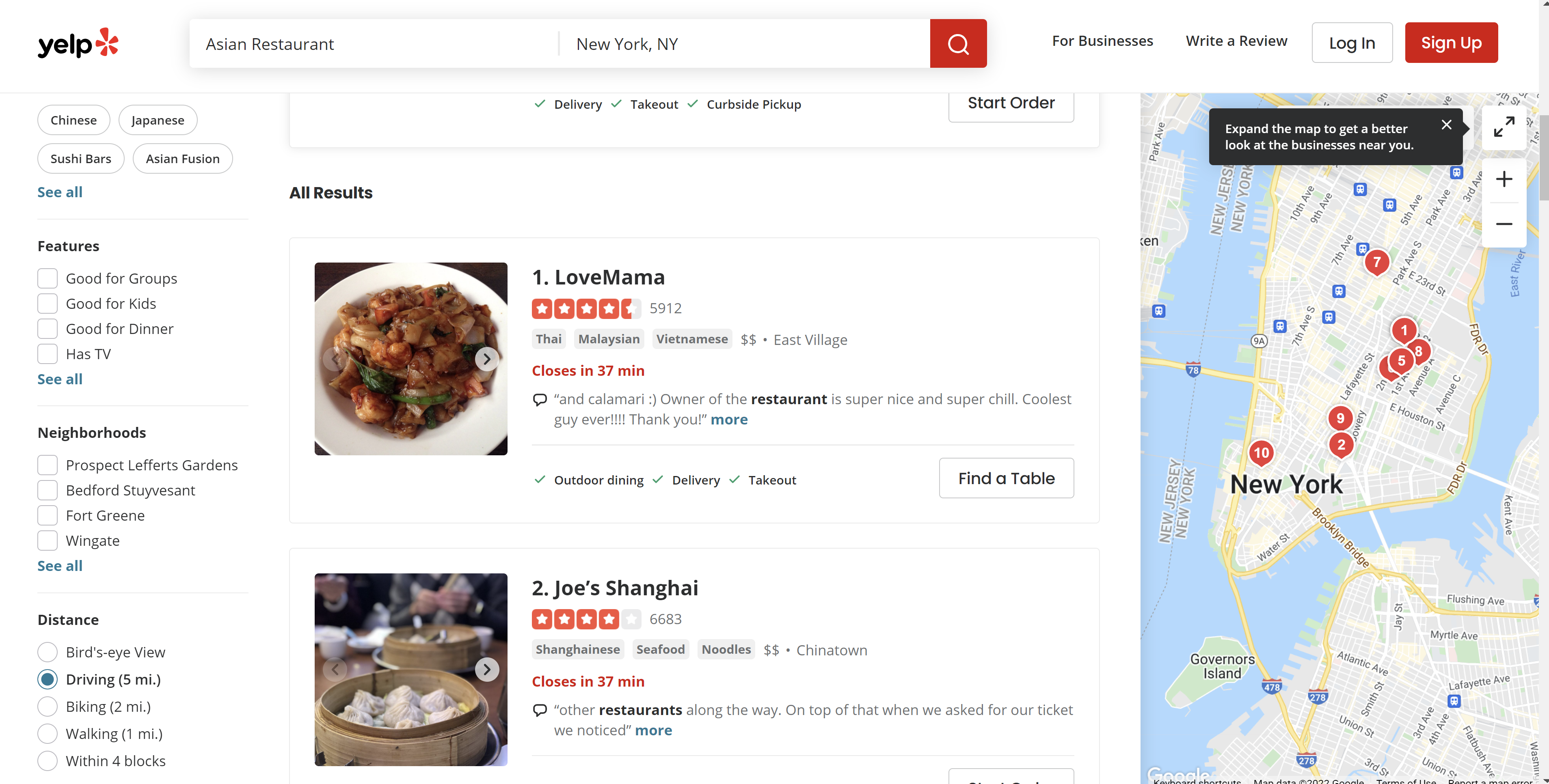
This is how the first page looks, I will need the restaurant names, cuisine types, ratings, total rating count, price range, and neighborhood area. I will go through all 24 pages on the site, but I won’t touch the review details yet, that would be the task for another day.
load in libraries
library(tidyverse)
library(rvest)
let’s start from the first page.
# clean all the variables from environment
rm(list = ls())
# read in the link of the website page
link <- "https://www.yelp.com/search?find_desc=Asian+Restaurant&find_loc=New+York%2C+NY&start=0"
page <- read_html(link)
# get the restaurant names from the first page
name <- page %>%
html_nodes(".css-1egxyvc .css-1m051bw") %>%
html_text2()
# use href in html_attr function to get the extension of each restaurant page, then paste together to get the entire url that I can use
restaurant_link <- page %>%
html_nodes(".css-1egxyvc .css-1m051bw") %>%
html_attr("href") %>%
paste0("http://www.yelp.com", .)
# since the ratings are not in numeric numbers, but in graphs, I inspected the scc code and did the following
rating <- page %>%
html_elements(xpath = "//div[contains(@aria-label, 'rating')]") %>%
html_attr("aria-label") %>%
str_remove_all(" star rating") %>%
as.numeric()
# obtain the rating count of each restaurant
rating_count <- page %>%
html_nodes(".reviewCount__09f24__tnBk4") %>%
html_text2() %>%
as.numeric()
# obtian the location area
neighborhood <- page %>%
html_nodes(".css-dzq7l1 .css-chan6m") %>%
html_text()
# I decided to go into each restaurant page to get the cuisine information, and make this a function since I will need to do it for every restaurant
get_cuisine <- function(restaurant_link){
restaurant_page <- read_html(restaurant_link)
cuisine <- restaurant_page %>%
html_nodes(".css-1fdy0l5 .css-1m051bw") %>%
html_text2() %>%
paste(collapse = ", ")
return(cuisine)
}
# use the sapply function to obtain the cuisine info from each restaurant page
cuisine <- sapply(restaurant_link, FUN = get_cuisine, USE.NAMES = FALSE)
# I also want to get the price range of each restaurant from inside the page
get_price <- function(restaurant_link){
restaurant_page <- read_html(restaurant_link)
price <- restaurant_page %>%
html_nodes(".css-1ir4e44") %>%
html_text2() %>%
{if(length(.) == 0) NA else .}
return(price)
}
price <- sapply(restaurant_link, FUN = get_price, USE.NAMES = FALSE)
# combine everything into a new tibble
restaurant <- tibble(name, cuisine, price, rating, rating_count, neighborhood)
View(restaurant)
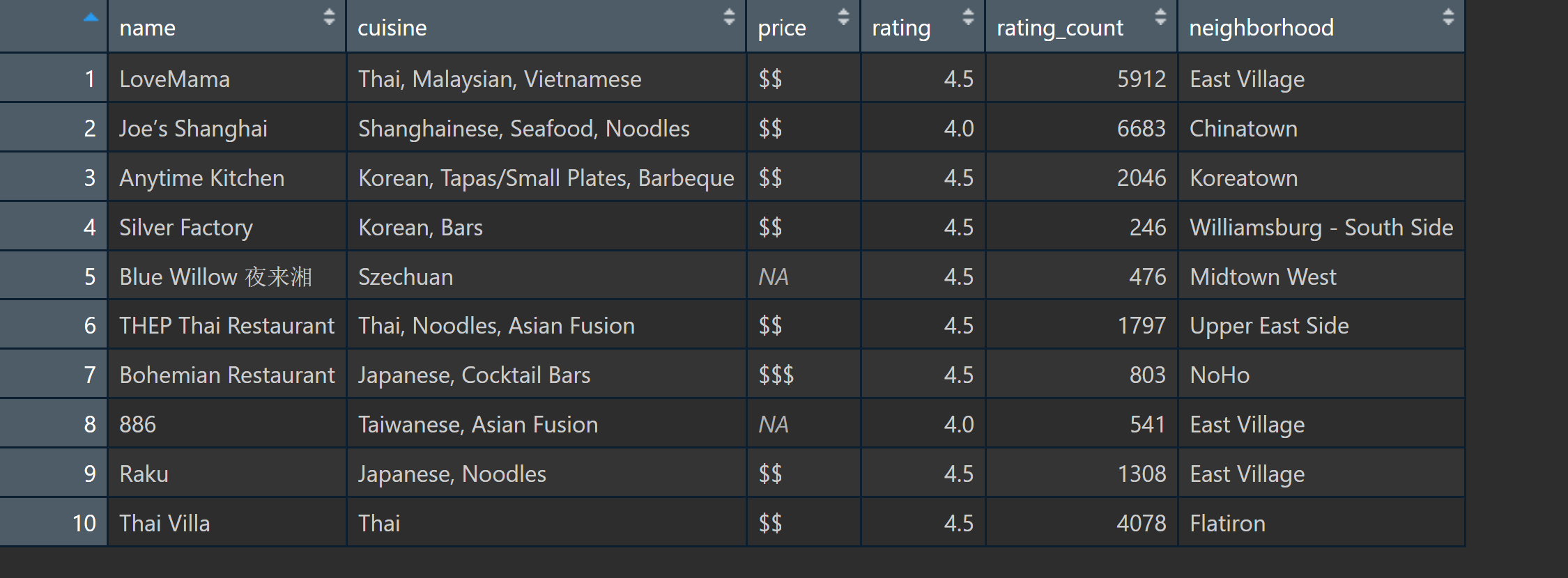
The information from the first page looks good, I will move on to scrape the rest of the 24 pages
# create empty vectors for variables
name_all <- c()
rating_all <- c()
rating_count_all <- c()
neighborhood_all <- c()
cuisine_all <- c()
price_all <- c()
# after inspecting how the pages change, the values after "start=" increases by 10 from 0
for (page_num in seq(from = 0, to = (24*10) - 10, by = 10)){
link <- paste0("https://www.yelp.com/search?find_desc=Asian+Restaurant&find_loc=New+York%2C+NY&start=", page_num)
page <- read_html(link)
name <- page %>%
html_nodes(".css-1egxyvc .css-1m051bw") %>%
html_text2()
restaurant_link <- page %>%
html_nodes(".css-1egxyvc .css-1m051bw") %>%
html_attr("href") %>%
paste0("http://www.yelp.com", .)
rating <- page %>%
html_elements(xpath = "//div[contains(@aria-label, 'rating')]") %>%
html_attr("aria-label") %>%
str_remove_all(" star rating") %>%
as.numeric()
rating_count <- page %>%
html_nodes(".reviewCount__09f24__tnBk4") %>%
html_text2()
neighborhood <- page %>%
html_nodes(".css-dzq7l1 .css-chan6m") %>%
html_text()
cuisine <- sapply(restaurant_link, FUN = get_cuisine, USE.NAMES = FALSE)
price <- sapply(restaurant_link, FUN = get_price, USE.NAMES = FALSE)
name_all <- append(name_all, name)
rating_all <- append(rating_all, rating)
rating_count_all <- append(rating_count_all, rating_all)
neighborhood_all <- append(neighborhood_all, neighborhood)
cuisine_all <- append(cuisine_all, cuisine)
price_all <- append(price_all, price)
print(paste("page", (page_num + 10) / 10))
}
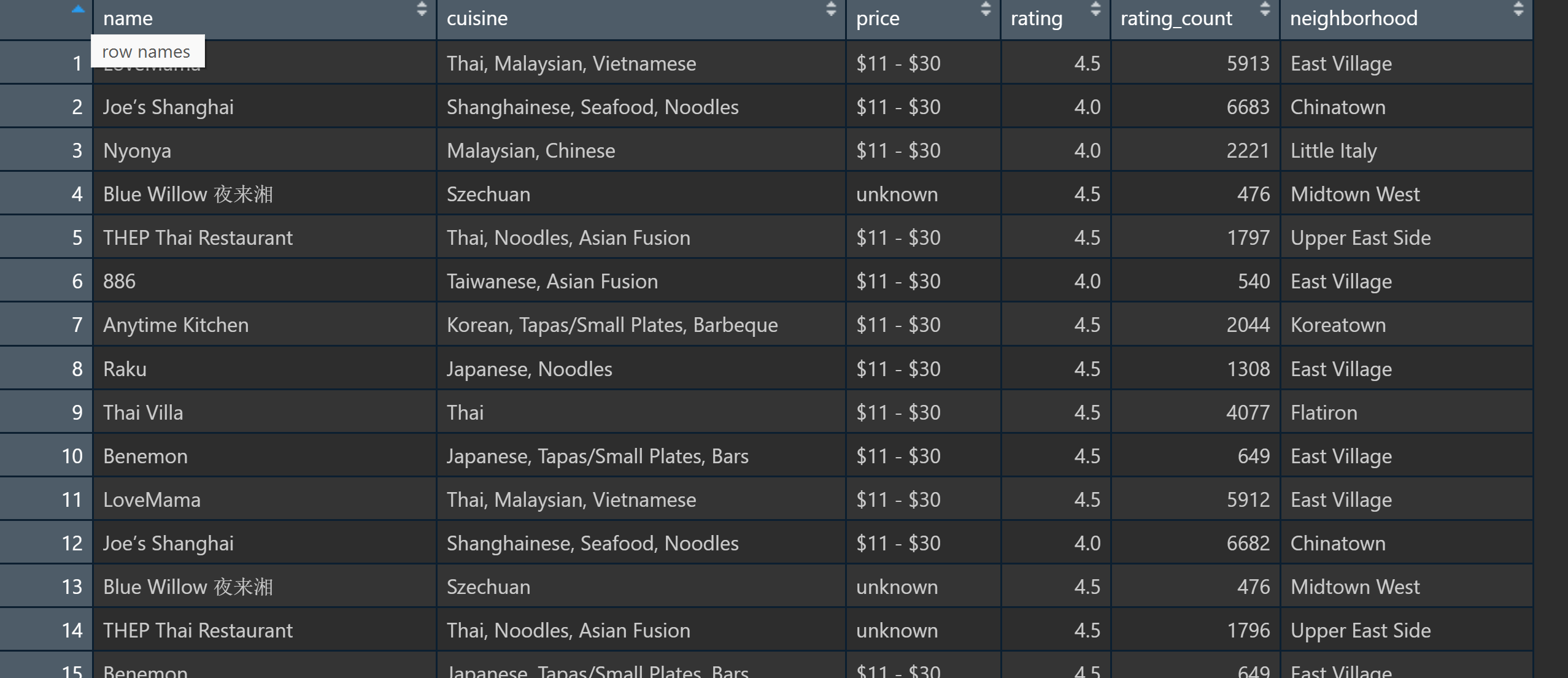
# after scraping through all the pages, I need to create a new tibble
restaurant <- tibble("name" = name_all,
"rating" = rating_all,
"rating_count" = rating_count_all,
"neighborhood" = neighborhood_all,
"cuisine" = cuisine_all,
"price" = price_all)
# the $ sign for price range doesn't make too much sense, after checking the guidelines on yelp.com, I will interpret it into something can be understood better
restaurant <- restaurant %>%
mutate(price = case_when(is.na(price) ~ "unknown",
price == "$" ~"Under $10",
price == "$$" ~"$11 - $30",
price == "$$$" ~"$31 - $60",
price == "$$$$" ~"$61 and Above"))
View(restaurant)
# save the data frame for future analysis
write_csv(restaurant, "C:/Users/haoli/Desktop/NY_asian_restaurants.csv")
Do you celebrate AAPI Heritage month? If yes, let me know what you do.